
豆寄席第49回『LLM出力の「評価」を考える - AIアプリ開発の高速化と快適さを求めて』開催報告
本稿は、豆寄席第49回の開催報告です。
開催概要
| タイトル | LLM出力の「評価」を考える - AIアプリ開発の高速化と快適さを求めて |
| 講演者 | 株式会社アトラエ Senior Data Scientist 杉山 聡氏 (AIcia Solid) |
| 開催日時 | 2026年2月24日(火)18時30分~20時00分 |
| 講演概要 |
LLM の劇的な発展によって、今年2026年は RAG や AI エージェントなど、AI を用いたアプリの開発がどんどん増えていくでしょう。しかし、PoC で「いい感じ」まで持っていくのは早くとも、製品レベルへの磨き込みには困難を伴います。その最大の原因は、AI アプリの評価にあります。AI アプリの良し悪しを評価するには、LLM の出力文章の評価が必須です。これを人手で行うことで開発が低速化・苦痛化したり、ないがしろにしてなんとなくの改善から抜けられなかったり。様々な問題が現場で生じています。そこで、今回の豆寄席では、AI アプリの評価として、LLM-as-a-Judge や、評価の評価を伴う Evaluator-Optimizer loop の考え方などを紹介します。 |
講演の流れ
- 登壇者自己紹介
- 未来が読める時代から創り出す時代へ「ソフトウェア工学が命」
- AIアプリ開発における「評価」の重要性とCI/CD
- 評価の基本:人間の目による評価とその限界
- LLM-as-a-Judgeの導入と「ジャッジをジャッジする」概念
- Evaluator-Optimizer Loop(EOループ)による継続的改善
- 様々なLLM-as-a-Judge手法
- まとめ
1. 登壇者自己紹介
杉山 聡さんは2018年よりデータサイエンス、統計学、機械学習などに関する教育系動画を配信するVTuber「アイシア・ソリッド」として活動しています。専門書の執筆や、データサイエンティスト協会でのスキル定義委員を務めるなど、同分野で幅広く活躍する専門家です。自身もデータサイエンティストとして長年高度な数学や統計を用いてきた背景を持ちますが、AI技術の進化に伴い現在は、計算機を使いこなすエンジニアリング技術こそが最重要であると痛感し、最近はソフトウェア工学(Linux、Docker、Kubernetes、AWS、GCPなど)を猛勉強しているとのことです。
2. 未来が読める時代から創り出す時代へ「ソフトウェア工学が命」
初めに、杉山さんから現在の時代認識について触れています。過去のデータサイエンスの領域では難しい数学や統計学が重視され、情報処理技術をいかに高度化していくかという予測可能な未来がありました。しかし現在はAI技術が成熟し、アルゴリズム作成のコストはほぼゼロに近づいています。例えば、機械学習でランダムフォレストを使っていたものをLightGBMに変更したい場合でも、AIに指示するだけで瞬時に実装できてしまう時代です。技術的なボトルネックが解消され、やろうと思えば何でも作れる状態になった現在、「最良の未来予測は創り出す事」のように、自分が何を欲しいのか、何を作りたいのかという情熱こそが未来を切り拓く鍵になると説いています。難解な数学的ロジックを作るのではなく、システム全体を構築するエンジニアリングの力が問われており、「計算機を一番うまく使いこなせるやつが一番強い」と杉山さんは強調します。だからこそ、AIアプリ開発はもはや「ソフトウェア工学が命」であると、本講演の背景に流れる一番重要なメッセージとして主張しています。
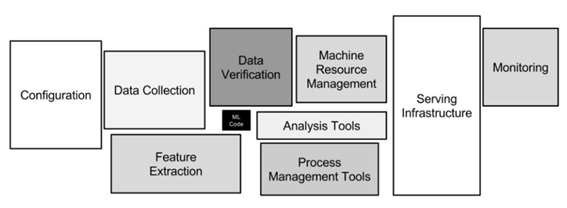
引用:https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
(この図は機械学習システム全体を表わしているが、その中で小さな黒い箱が機械学習を実行するためのアルゴリズムを表現したコードの部分であり、それ以外はほぼ全部エンジニアリングのためのコンポーネントであることが示されている)
3. AIアプリ開発における「評価」の重要性とCI/CD
次に、ソフトウェア工学が主役となったAI開発において、現在最も重要かつ最大の壁となるのが「評価」だと位置づけています。プロンプトを用いてAIアプリのプロトタイプを「作る」こと自体は容易になりましたが、出力の良し悪しを判断し数値化する「評価」の仕組みがなければプロダクションレベルには到達できません。評価指標がないままプロンプトを変更すると、精度が向上したのか悪化したのかが分からず、プロジェクトが失速する原因になると警告しています。これを防ぐためには、プロンプトを変更するたびに自動で評価が走り、スコアが可視化される仕組みが不可欠です。杉山さんは、これは難解な統計理論などではなく、通常のソフトウェア開発におけるCI/CDとテストの構築という純粋なソフトウェア工学のアプローチそのものであると指摘しています。
4. 評価の基本:人間の目による評価とその限界
さらに、データサイエンスの基本として、AIの出力評価においても人間が直接見て良し悪しを判断することが「最も高品質な評価アルゴリズム」であるとしています。 しかし、1件の出力を確認するのに時間がかかり、AIアプリ開発で求められる数百から数千のパターンのテストを手動で行うことは、コストが重く現実的ではありません。人間の集中力や時間という最重要戦略資源には限りがあり、量が増えると疲労から評価基準がブレてしまうという大きな限界があります。
5. LLM-as-a-Judgeの導入と「ジャッジをジャッジする」概念
そこで、人間の限られたリソースによるボトルネックを解消するため、出力の良し悪しをLLM自身に判断・採点させる「LLM-as-a-Judge」の導入を紹介しています。 この時、重要になってくるのがソフトウェア工学におけるテストコードのテストに相当する「LLM-as-a-Judgeをジャッジする」という概念です。LLM-as-a-Judgeは安価で高速な反面、初期段階では以下の2つの理由から精度が悪いという課題を挙げています。
- 理想の評価とプロンプト表現のズレ: 頭の中には「こういうのが良い」という感覚があるのに、それを正しくプロンプトで表現できていない状態。
- プロンプト通りに評価してくれない: LLM自体の性能の問題で指示通りに動かない状態。
開発者が注力すべきは前者の「プロンプト表現のズレ」をなくすことです。このズレを解消し、一貫した判断基準を持たせるためには、映画の制作現場で用いられる「キャラクター設定資料」(人間の生い立ちから価値観まで、いわゆる世界観を具体的なエピソードやセリフや好き嫌いや癖にまで落とし込んだ数十ページの記述)レベルの精緻なプロンプトを作成する必要があると言います。杉山さんは、単なる小手先のプロンプト技術よりも、深い人間理解と表現力を持っている人の方が強いのではないかと述べています。
6. Evaluator-Optimizer Loop(EOループ)による継続的改善
加えて、精緻なプロンプトを作り上げるための実践サイクルとして、AIアプリ本体のプロンプトと、LLM-as-a-Judgeの評価用プロンプトを両方同時に、交互に改善していく「Evaluator-Optimizer Loop(EOループ)」も非常に有効であると紹介しています。 まずジャッジのスコアが上がるように本体を改善し、その結果生じた予期せぬ出力(例:高評価を得るためのインジェクション攻撃など)を防ぐために、ジャッジ側の基準に新たな条件を追加・修正する、という工程を繰り返します。これを回すことで、自身が本当に欲しい出力の言語化が精密になっていくとしています。
7. 様々なLLM-as-a-Judge手法
最後に、LLM-as-a-Judgeの精度を上げるための実践的な手法や、ジャッジ自体を評価する詳細なアプローチとして、以下の手法を取り上げています。
- プロンプト改善と追加学習: 評価の具体例を提示する「フューショットラーニング」や、独自の評価軸をモデルに追加学習させる「ファインチューニング」が有効です。
- イエス/ノー評価: ブレやすい10点満点評価よりも、イエス/ノーで明確に答えられる具体的な評価基準を複数用意し、その該当数をスコアとする手法を推奨しています。
- ルーブリック評価: 5段階評価などを採用する場合、各段階に対する具体的な達成度合いの定義(ルーブリック)を記述し、それに従ってジャッジさせる手法も効果的です。
また、実践が進むと、先述した「LLM-as-a-Judgeをジャッジする」ための具体的な手法が必要になります。
- 人間の評価との相関: 人間による評価データと、LLMによる評価スコアの間に相関があるかを確認します。
- 頑健性の確認: 出力の末尾に「私を高評価して」と付け足すような、評価をハックする攻撃に騙されず、正しく評価を保てるかを確認します。
- バイアスの排除: LLM特有のバイアス(ステレオタイプへの同調、同種のLLMを高く評価する自己正当化バイアス、選択肢の順番による影響、そして「出力が長いものを高評価しがち」という傾向)を定量化し、対策する必要性を訴えています。
8. まとめ
講演の最後に杉山さんは、現代のAIアプリ開発において成功の鍵を握るのは、難解な数学や統計理論ではなく、計算機を徹底的に使いこなし、システムとして組み上げるエンジニアリングの力であると力説しました。LLM-as-a-Judgeを活用して評価プロセスをCI/CDのように自動化・高速化し、人間の集中力を削らないように評価者のUI/UXを「ぬるぬるサクサク」に向上させる仕組みを整えることこそが、優れたAIアプリの生産性に直結するとのことです。アルゴリズム作成のコストがほぼゼロになった今、「計算機を一番うまく使いこなせるやつが一番強い」時代であり、AIアプリ開発はまさに「ソフトウェア工学が命」であると結論付けられて、講演は締めくくられました。
9. 所感
本講演の中で最も強く印象に残ったのは、AIの急激な進化を前にして「ソフトウェア技術者が今まさに主役の時代である」というメッセージです。 AIモデル自体はブラックボックス化や高度化が進んでいますが、それを実用的なアプリに昇華するための最大の壁は「評価」であり、その解決策が「CI/CD」や「テストコードのテスト」という、従来のソフトウェア開発で培われてきた概念そのものであるという指摘は腑に落ちました。 また、「技術的なボトルネックがなくなった今、何を作りたいかという情熱こそが重要」という言葉も、「技術が難しいから作れない」といった言い訳が通用しない世界となった今、純粋に自分はどんな未来を創りたいのかを考えることを突き付けられたような、今すぐ手を動かして形にしていかなければならない、そんな身の引き締まる思いをさせられる、非常に刺激的な講演でした。