
豆寄席第45回『人工知能にどのぐらい「知能」があるか?感情と論理の2つの観点から考える生成AIの現在と未来』開催報告
本稿は、豆寄席第45回の開催報告です。
開催概要
| タイトル | 人工知能にどのぐらい「知能」があるか? 感情と論理の2つの観点から考える生成AIの現在と未来 |
| 講演者 | 株式会社豆蔵 デジタル戦略支援事業部 石川真之介氏 株式会社豆蔵 デジタル戦略支援事業部 吉野惇志氏 |
| 開催日時 | 2025年8月26日 (火) 18時30分~20時00分 |
| 講演概要 |
今回の豆寄席では、豆蔵の独自研究により明らかになった生成 AI の実情と、AI と社会の今後についてお話しいたします。 今回は、私たちが国際会議 NAACL 2025 のワークショップで発表した論文の内容や、進行中の研究の内容にもとづき、LLM の「知能」がどこまで到達しているかについて紹介します。 |
講演の流れ
■ プロローグ ~より人間らしく
■ 講演者自己紹介
■ 豆蔵 AI-Tech チームのご紹介と AI と社会の未来像
■ LLM による業務の変革
■ 2つの論文に基づく、2つの軸による AI の振る舞いの評価
・感情: 感情を持たずとも感情は表現できるのか?
・論理: 判定方法を教えずに情報を論理的に解釈できるか?
■ まとめ・最後に
プロローグ ~より人間らしく
講演の冒頭では、人工知能はそもそも人間をお手本として設計されており、人間のような知的な活動を実現することが目標とされてきたといった事が述べられました。
本講演は、そんな人工知能の「人間らしさ」に関する豆蔵AI-Techチームの探求の成果がまとめられたもので、感情と論理という2つの側面から独自研究で得られた知見をふまえ人工知能の知能がどこまで人間に近づいたかについてお話頂きました。
豆蔵AI-Techチームのご紹介とAIと社会の未来像
豆蔵AI-Techチームは下記を使命として活動しています。
「先端技術の学術的な探求を起点として、
社会の未来像を描き出すことが私たちの使命です。
その未来像を具現化するため、
AI技術の社会実装を通じて新たな価値創造に取り組みます。」
AI-TechチームはAIが浸透していく社会の未来像を描くとともに彼らが挑む挑戦課題をまとめています。
AI-TECHの挑戦課題の1つである「説明可能AI」に関連して、「AIに論理的な仮説検証が行えるか?」という問題に、また、「AIの感情表現」に関連して、「AIに感情を持った振る舞いができるのか?」という問題にAI技術チームは取り組み、それらの成果について以降のように詳しくお話頂きました。
LLMによる業務の変革
続いて講演ではAI技術の最近の進化の流れについて特に重要な点についてご説明頂きました。
2010年代:深層学習による画像認識の飛躍
• 出来事: 深層学習を用いた画像分類で人間を超える精度を達成
• 手法: 膨大な画像と正解ラベルのペアを学習
• 課題: 高精度である一方、「なぜその分類になったのか」を説明することは困難
深層学習の発展により、ユーザーの入力に応じて適切な応答を生成できる大規模言語モデルが登場しました。
2020年代前半:大規模言語モデル(LLM)の登場
• 代表例: ChatGPT
• インパクト: 応答が「言語を理解している」と思わせるレベルに到達し、驚きをもって迎えられた
• 要素技術: Transformer がブレークスルーを支える基盤となった
大規模言語モデルの学習方法と驚くべき能力
• 学習方法:
➤ 膨大なテキストをデータとして「次の単語(トークン)予測」を繰り返し学習
➤ 言語の意味や文法を直接教え込むことはしていない
• LLMの驚くべき能力の例:
➤ 翻訳が可能
➤ 高品質なプログラミングコードの生成も可能
説明されたようにLLMは続きのトークンの予測を繰り返しているわけですが、そのようなプロセスにより高品質な文章やプログラミングコードが出力されることは改めて考えると驚くべきことで、なぜそのようなことが可能なのかを直感的に理解するのは困難に思えます。
LLMにより少人数のチームが莫大な利益を上げる事例なども紹介され、LLMの普及により社会が急速に変化しつつあることが改めて感じさせられます。
話題は徐々に本講演の核心へと迫っていきます。
LLMと知能の問い
• LLMは「それらしい言葉」を生成できるようになった
• しかし「本当に知能を有しているのか?」という根本的な疑問が残る
• → 本講演のテーマとも密接に関わる問題意識
感情:感情を持たずとも感情は表現できるのか?
続いて登壇者お二人が最近発表された論文の概要をご説明いただきました。こちらの論文は自然言語処理分野でのトップカンファレンスであるNAACL2025内ワークショップに採択され、お二人はポスター発表を行いました。
タイトル:
AI with Emotions: Exploring Emotional Expressions in Large Language Models
(「感情を有するAI: LLMの感情表現を探索する」)
• doi: https://doi.org/10.18653/v1/2025.nlp4dh-1.51
• arxiv: https://arxiv.org/abs/2504.14706
• 日本語解説記事: https://www.mamezou.com/techinfo/ai_machinelearning_rpa/ai_tech_team/17
論文の概要
■ LLMに感情状態を持っているかのような応答ができることを示し、これを達成するためのプロンプト作成の基本的な考え方を示した
■ LLM自体は感情を持たなくても、LLMのロールプレイにより役割を与えられた存在であるAIエージェントは主体的に振る舞える
(「LLM-エージェント」は「脳-人格」の関係と類似的)
この論文の出発点となる問題設定は、AIには感情を持っているかのような応答ができるのか?というものだったとのことです。
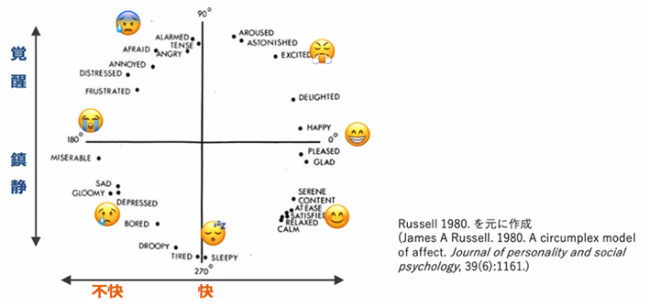
論文では、Russell感情円環モデルを用いて、感情状態を定義し、応答で表現された感情を定量評価するために感情分析モデルを用いています。
分析ツール:Russell円環
■ 心理学分野で、感情(affect または emotion)を分析するための標準的なモデル
■ 感情状態を「快-不快」「覚醒-鎮静」という2軸で分類するとほぼ円環状に並ぶ
(感情データを、統計学の主成分分析の手法に掛けたようなもの。快-不快軸が第1主成分)
人間の様々な感情状態が数学的に2つの量で良く表現できるというのはそれ自体大変興味深いと感じました。
本研究では、プロンプトで感情状態を指定したうえで質問を入力し、得られた応答を感情分析モデルで分析し、指定した感情状態がどの程度正しく表現できたかを定量的に調べています。
続いて感情状態を指定した場合のLLMの応答例が紹介されました。同じ質問であっても指定された感情状態の違いにより応答の様子が異なっており、LLMの出力が指定した感情状態を反映できていることがよくわかり興味深いです。


普段LLMを利用していてLLMがある程度の感情表現が可能であることは感覚的にはわかっていたことではありましたが、この論文ではこの点を定量的かつ包括的に調べたことが重要であると言えそうです。
この論文の内容について下記のようにまとめられました。
論文の結論
■ LLMには感情を持っているかのような受け答えができる
・結果を定量的かつ、複数の感情にわたって包括的に示した
■ 複数の LLM モデルでおおむね近しい結果
・サービス実装を考える際、選択肢の幅も広い
■ RAGやモデルのファインチューニング無し・プロンプトエンジニアリングのみで達成可能
・非常に低いコストで試しにアプリケーションの概念実証が可能
➤AIに “より人間らしい” 応答が可能になる
➤弊社であれば、サービス実装の支援も可能です
・介護・福祉業界、ゲーム業界 …etc.
論理:判定方法を教えずに情報を論理的に解釈できるか?
続いてAIと論理に関する研究へと話題が移ります。こちらの論文もトップカンファレンスに採択されたそうです!

論文のタイトルに含まれる「イドラ」は、フランシス・ベーコンが提唱した概念で、人間が陥りがちな偏見・思い違いであり、イドラには4種類あることが紹介されます。このうち、種族のイドラは、人間誰もが持つ偏見・思い違いのことで、この種族のイドラに相当する現象がLLMにおいても観察されたというのがこの論文の内容であると言います。
本研究の動機づけについては下記のように説明されました。
取り組みのモチベーション:LLM に仮説検証ができるか?
ビジネスにおける課題解決を考える上での基礎的な要素である仮説検証能力は、
AI エージェントが精度良く振る舞うためにも重要な要素となると考えられる。
→ 仮説立案・検証方法策定を LLM が担うことができるかの研究を進めている
※ 事実でないことを言うかどうかではなく、論理的に破綻していないかが検証したい内容
GPT-4o では、下に示す例のように、数列の法則性を聞くような簡単な問題設定でも、「それっぽい」だけで間違った仮説を立てることが紹介されます。
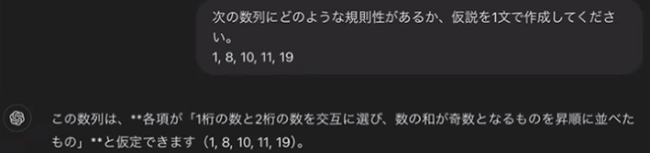
確かに出力は一見それらしく見えますが、内容はいい加減です。
研究では、下記のように、724個の数列に対し、5つのLLMに規則性を答えさせるという実験を行ったそうです。

人間にとっても難しそうな問題も含まれそうですが最近のLLMがどの程度うまく対処できるのかという点が興味深いですね。
多数のLLMの出力の妥当性を評価するためにもLLMを使ったそうです。LLMは自らの誤った出力を誤っていると判断することはできるのですね。人間が検算で自分のミスに気づくようなものでしょうか。このような点も技術的にも面白いと感じました。
モデルごと、数列ごとの精度に関して下表が示されました。
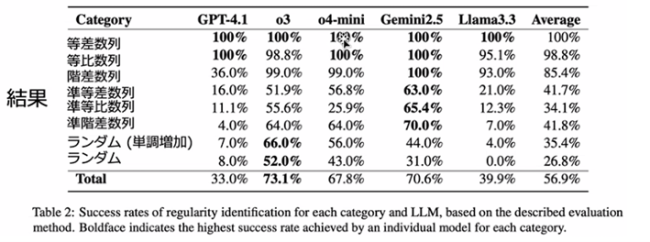
ランダムな数列に対しては「規則はない」などと出力するのが正解ですが、いい加減な規則性を出力するケースが多く観察されたそうです。
また、下記のように、ランダムな数列に対して、なんとか法則性を説明しようとしたケースもあったとのことです。

「自己検証型」のモデルであるo3, Gemini 2.5 Flash Thinkingで誤った出力が得られた例も示されました。

このような数列とLLMを用いた実験から、どの LLM も似たような論理的間違いをすることがわかり、生成 AI における「種族のイドラ」ではないかと指摘する論文を投稿し先述のようにEMNLP2025 findingsに採択されたそうです。
まとめ・最後に
講演は下記のように締めくくられました。
■ AIに、ある意味において知能はあると考えて良いように思われる
・ただし、人間の知能の全てをカバーできているとは言えない
・その実現は AGI 誕生の瞬間と言えるかもしれない
・パターン認識をしているだけなのになぜ知能らしきものが現れるのかは不明
■ 一方、できないことがあるのも確実
・自らの意志、欲求といった根源的な要素が欠けていることが関連しているかもしれない
■ 世界中の研究者がさまざまな観点で研究を進めることにより、現在の人工知能の研究を突破し、人間の知能に対する理解も進むことを期待
・われわれもそこに少しでも近づく手助けができるよう、がんばって探求していきます
所感
本講演ではトップカンファレンスに採択されるようなLLM分野の最先端の研究テーマに触れることができ大変新鮮でした。AI-Techチームは本講演で話されたような興味深いテーマに取り組んでおり今後の研究成果にも期待したいと思います。もし今後機会があったら私自身もこのような興味深いテーマの探求に携わることができたら面白そうだと感じました。
今後の 豆寄席 へのご参加もお待ちしております!