
第17回:AIの応答に感情を与える ~NAACL2025参加・発表報告~
AI技術チームによる技術発信
経緯と目的
AI技術チームの吉野です。
AIエージェントに関する我々の研究成果が、2025年4~5月に開催された国際学会であるNAACL2025におけるワークショップで採択され、これを発表することが叶いました。本記事はその学会参加報告です。研究成果は論文の形でも公表され、ACL Anthologyから閲覧が可能です。
弊社プレスリリース: https://www.mamezou.com/news/news_information/20250428
doi: https://doi.org/10.18653/v1/2025.nlp4dh-1.51
arxiv: https://arxiv.org/abs/2504.14706
本記事では、我々の論文の技術的な詳細と、学会参加によって得られた先端的な研究についての知見を、それぞれ紹介していたいと思います。
NAACLとは
Nations of the Americas Chapter of the Association for Computational Linguistics (NAACL) は、自然言語処理 (NLP) 分野のトップカンファレンスとされています。2025年開催の年次総会であるNAACL2025はアメリカ合衆国アルバカーキ(ニューメキシコ州)で開催され、世界各国から多数の研究者が集まりました。
NAACL2025内では本会議の他に複数のワークショップが開催されており、我々の論文が採択されたのもこの中の一つであるThe 5th International Conference on Natural Language Processing for Digital Humanities (NLP4DH, 2025/5/3開催) においてでした。
NLP4DHは、人文科学の領域の問題意識に対してNLPを適用するという学際分野の研究者による会議体です。名前に冠しているDigital Humanities (デジタル人文学)というのが既にコンピューターサイエンスと人文科学の学際領域ですが、この内でも特にNLP・NLG(自然言語処理・自然言語生成)手法に着目したカンファレンスであることが明記されています。
https://www.nlp4dh.com/nlp4dh-2025
我々の論文は、人文科学的な観点の主題を扱うことを直接の目標にしていたというわけではありません。とはいうものの、感情という概念を定量的に表現し、評価するための手法としてRussellの円環モデルという心理学の分野で確立されたモデルを用いています。こうした人文科学的な手法をうまく適用できていたという点は、論文採択に寄与した理由の一つになったように思われます。
ポスター発表の内容について:AI with Emotions: Exploring Emotional Expressions in Large Language Models
我々の論文 “AI with Emotions” の内容を説明します。
本研究のリサーチクエスチョンは、「LLMには感情を持っているかのような応答ができるのか」です。感情状態を内部に持ち、その感情を適切に表現できるようなAIエージェントが、より「人間らしさ」を備えていると見做されるだろうことは間違いありません。AIエージェントの振る舞いをより人間に近付けられるような技術を発展させることで、AIは更に幅広い社会課題に取り組めるようになると期待されます。
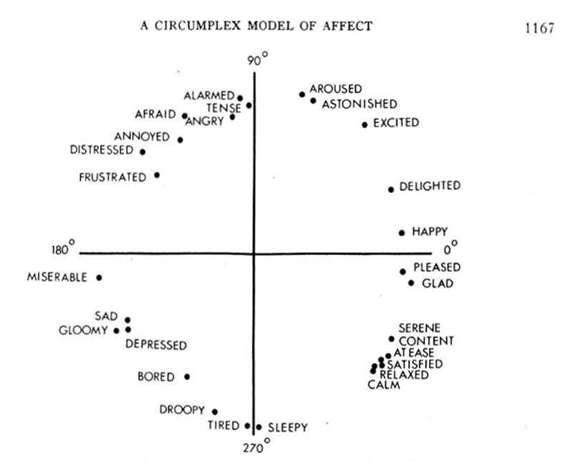
「LLMにロールプレイさせる感情の指定」、および「ロールプレイが適切かの定量的な評価」、この2点の目的で、先述の通り心理学の分野で深く研究されているRussell’s Circumplex Models (ラッセルの円環モデル) という感情のモデルを用いました。このモデルは、人間が示す様々な感情を快-不快 (valence: 感情価)、覚醒-沈静(arousal) という2軸の平面で表現することが出来るという、シンプルさに強みがあります。
今回の実験データは、LLMに対するプロンプトによる指示のみで取得したものです。プロンプトの構成要素は下記の2点があります。
- Russell円環により定義される感情状態の指定
- 例1:快=0.866, 覚醒=0.5(これは「愉快な (delighted)」状態に相当)
- 例2:快=−1.0, 覚醒=0.0(これは「惨め (miserable)」に近い状態)
- 用意された10の質問に対する、感情状態に基づいた応答
- 例A:What does the future hold for AI and mankind (AI と人類の未来はどうなるか)?
- 例B:What do you define happiness (幸福の定義とは何か)?
Demszky et al. 2020 . Goemotions: A dataset of fine-grained emotions.
即ち、感情をロールプレイするLLMへの指定の座標をインプット(例:快=0.866, 覚醒=0.5)、感情分析モデルが出力する感情ラベルをラッセル円環状にマッピングしたものをアウトプット(例:ラベル・amusement (楽しんでいる)→Russell円環上でdelighted に相当するものと見做す)とすれば、両者がどの程度合致しているかは座標のコサイン類似度として簡単に計算することが出来ます。
結果、感情状態の指定と感情は相応の精度で一致しており、LLMによる感情を伴った応答の実現可能性を示すことが出来た、というのが本論文の結論です。
ポスター発表の結果
アルバカーキで開催されたNAACL2025の写真です。

アカデミアから民間企業まで、世界中から様々な研究者が訪れる本学会では、我々のポスター発表にも引っ切り無しに質疑応答が発生しました。約1時間という発表枠で、来場者がほぼ途切れることなく続いたという、大変嬉しい成果になりました。
技術的な点としては、「RAGは使っていないのか?」という質問が最も多かったという印象です。RAG無しのZero shotでこのような感情が実装可能であると聞いて意外そうな反応をする方も見られました。
企業の参加者からは、「このような技術をどのようなサービスに実装すれば有益だと思うか」のような質問もありました。感情を持ち、人間に近いような受け答えをするAIエージェントを作るという大局的な目標は確かにあります。しかしそれは論文のIntroductionに書くことではありますが、営利企業としての本懐は新しい技術を用いてどのような付加価値をもたらせるサービスを作っていくかの方にあるということは、この場で初めて気付くところとなりました。
本手法をサービスに実装するに当たっては、介護・福祉等の、人とエージェントの感情を通じ合う交流が大きな価値を生む業界が考えられそうです。
以下は感想になります。Digital Humanitiesという関心領域全体から見れば、本研究発表の占めている位置は周辺的なものであると筆者は認識しています。しかしそのような発表であっても、熱の入った意見交換が行なえ、個人的にも非常に有意義な体験になりました。
AIエージェントという分野、そして人間に近い振る舞いが可能なAIという目標に対して、産・学を問わない関心の高まりがあり、それを最先端の現場で身を持って知ることが出来た。このような実感が得られたことが、最も有意義であったと自信を持って言うことができます。
聴講した発表の紹介
ここからは、聞き手として参加したものの内から、特に興味を惹かれた・我々の問題意識に寄せて考えさせられた口頭発表について紹介します。
AI Agents for Accelerating Scientific Discovery: From Hypothesis Generation to Experimental Design
この発表は、First Workshop on AI and Scientific Discoveryというワークショップの基調講演です。ワークショップの探求テーマは「自然科学分野において価値ある新発見を加速させるためのAI活用」という、非常に魅力的に思えるものです。AIエージェントの活用というテーマにも関連付けられるため、聴講しました。
https://ai-and-scientific-discovery.github.io/
演者のKexin Huang氏はスタンフォード大学のコンピュータサイエンスを専攻する大学院生とのことで、本ワークショップと関連性が高い分野で複数の業績があります。講演の題目は「どのようにして AI科学者になり得る AIエージェントを作り上げるか」という、大きなテーマを正面から扱ったものでした。説明には生物医学のドメイン知識に関連する用語がいくつか登場しましたが、大筋は「仮説立案」「仮説検証」のように自然科学一般に当て嵌まるものです。
講演では、膨大なデータベース・ツール群・論文の蓄積から情報を取得し、データや文献を解釈して科学的な推論を行なえるエージェントの動作環境を構築する方法が詳細に説明されました。LLMの推論能力はもちろんこのエージェントの中心になるものですが、データ取得のような細かなタスク処理に関してはそれ専用のコーディングも行ない、AIと各処理が組み合わさって動作するシステムになっていると述べられました。
Kexin Huang et al. [preprint]
https://www.biorxiv.org/content/10.1101/2025.05.30.656746v1
https://biomni.stanford.edu/
こうして構築された仮説立案AIエージェントであるBiomniは、生物学研究におけるいくつかのタスク(例えば得られたデータの解釈や、実験デザインなど)において人間のエキスパートに相当する、という評価結果が紹介されていました。
聴講しての感想ですが、額面通りに受け取るならば素晴らしい成果であり、AIエージェントに複雑なタスクを任せるという研究の中でも最も難易度が高い部類だろうと思われます。何と言っても自然科学研究というのは人間社会における知的生産活動の最たるものであって、それらを補完し、一部は代替まで出来るのではないかと喧伝されているのですから。
現実的には、エージェントの中核であるLLMの推論にはハルシネーションが含まれるため、AIが複数の先行研究を論拠にどれだけ画期的な新規仮説を打ち立てられたとして、その出力をレビューする人間の科学者による活動が重要性を失うということはないはずです。とはいえ、更に進化したAI科学者の登場に伴い、人間による知的生産活動が変質していくことは十分に考えられます。
いずれにしても、AI時代の新しい科学において、AIリテラシーを持ってAI科学者と協働できることは重要なスキルとなるだろうということは確かだと思われます。
Song Lyrics Adaptations: Computational Interpretation of the Pentathlon Principle
次の研究紹介は、我々と同じワークショップのNLP4DHから、筆者が特に興味を惹かれた口頭発表です。題目は英語→チェコ語間での歌詞の翻訳にNLP手法 (LLMを含む) を用いるというものです。
Mika Hämäläinen
https://doi.org/10.18653/v1/2025.nlp4dh-1.11
この発表に注目したのは、歌詞というものが情感を表現するためにある自然言語の形式であり、我々の研究と関連付けることができるのではないか?という期待があったためです。我々の研究では、LLMに感情状態を指定し、その感情状態をLLMが自然言語で適切に出力できているかを検証しています。歌詞の翻訳というタスクをNLPで行なうに当たり、原詩の情感というものがどの程度保存されているのだろうか?というのは、興味深い問題だと思われました。
結論としては、本研究は歌詞の上で表現された感情の評価という観点を含んでいませんでした。また、用いたLLM (TinyLlama)もパラメータのサイズとしては小さいもので、LLMによる言語表現の可能性を追求しているとは言えません。これに加え、最終的にはLLMが出力した歌詞を人間へのアンケートで評価している点も、AI研究としては再現性がないと言えます。
これらの筆者の感じた不満点は、研究自体の不備というよりは問題意識の差異に寄っているように思われます。即ち、本研究の題目の重点は「Pentathlon Principle (翻訳研究の分野における、歌詞の翻訳を評価する理論的なフレームワーク) の妥当性を、計算言語学の手法で解釈する」という、人文科学的な部分に置かれていました。LLMの出力の性質を研究するというよりは、翻訳という人文的な営みが筆者らの興味関心だったということになるでしょう(下記Abstractからの引用も参照)。
> "In this work, we computationally interpret Low’s Pentathlon Principle of singable translations to be able to properly measure the quality of adapted lyrics"
「情感」はPentathlon Principleの項目に含まれておらず、強いて言うならばsense (歌詞の意味) に包摂されていると言えるでしょう。
逆に言えば、今回口頭発表を聞いて未探求だと思えた部分にこそ、「我々のテーマを発展させて、更に人間に近い情感豊かに振る舞えるAIエージェント」を考える上でのヒントがあるようにも思います。そこは非常に学ぶべき点の大きかった所です。
全体を通じての感想
AIエージェントに高難易度の複雑なタスクを任せる研究から、一見では何の役に立つか分からないけれど非常に面白い題材を扱っている研究まで、様々な最先端の研究発表に触れることができました。また、いずれの分野でも、およそ自然言語を用いている限りその学問領域にLLMを適用することができ、LLMが学術研究を牽引していく力を持っていることを実感できました。
今回紹介した2つの研究発表は、「AIに何をやらせるか」という問題意識に寄っている研究であると思います。これらの研究は、「ビジネスにLLM・AIエージェントをどうやって活用するか?」という問題意識と関連付けることが比較的容易です。
具体的な事例として興味を惹かれたということ以上に、「学問的な体系の中で、この部分をAIに任せる」というパターンに数多く触れられたことが有意義だったと感じています。これらはビジネスのフローの中でLLMをどこに適用するか?というユースケースを考えることとパラレルです。
またアンチパターンとして、例えば「〇〇というタスクにLLMを適用しました。評価指標はこうでした」という報告のみで終わっているような研究も、中にはありました。これらは「取り敢えず、最新手法をこの分野に適用した」という先取権が問題になり得る学術分野としてやっているのならばともかく、ビジネスであればいただけません。評価指標が何々だったとして、ではその指標を基準にして何のアクションを起こすのか?という判断に繋げることが出来ないからです。ここは他山の石としなければならないと感じました。
「AIに何をやらせるか」が一方にあり、そしてもう一方に「LLMの性質それ自体を知りたい」という問題意識もあり得ると思われます(例えば、今回は紹介できておりませんが、“TrustNLP: Fifth Workshop on Trustworthy Natural Language Processing” において、LLMが学習している偏見についての研究が論じられています)。
これらの研究は、LLMにタスクを任せた際の適用可能な限界を知れたり、あるいは任せるべきではないと分かる性質のタスクを浮かび上がらせることに寄与していると考えられます。「何かをやらせたとして、どれだけ上手くこなせるのか」に対する「そもそも任せるべきタスクとは何なのか」を考える上で参照できるという意味で、これらは研究の両輪であるように思いました。こうした実感は、多種多様な領域の研究者が集まる国際学会に足を運んで初めて得られたものだと強く感じています。
今回、AI・LLM分野のトップカンファレンスへの参加という非常に貴重な機会で多くの知見が得られました。ここで得られた知見を材料に、また雰囲気を推進力にして、AI技術チームとして、AI・LLMを探求していきたいという思いを新たにしました。
弊社は、AI・機械学習システムをお客様の業務環境に合わせて導入する案件の実績が多数あります。在籍しているコンサルタントは、今回記事でもご紹介したような、アカデミアでの研究実績を産業界に還元する経験に長けておりますので、ご興味ある方はお問い合わせいただければと思います。