
第14回:AIによる自動ソフトウェア開発の可能性:大規模言語モデルを評価するベンチマーク(SWE Bench)と最新の取り組み
AI技術チームによる技術発信
はじめに
AI Techチームの藤堂です。
近年、大規模言語モデル(LLM)の発展により、コーディング支援の分野で目覚ましい進歩が見られます。LLMは、プログラミング言語の文法や構文を理解し、コードを生成できるだけでなく、問題解決のためのアルゴリズムや設計案の提案も可能になってきました。
私の周りでも、多くの開発者がLLMを活用してコーディングの効率を上げていると聞きます。実際に、私自身も初めて触れるプログラミング言語であるReactやKotlinを使って、わずか2、3日でアプリケーション開発ができるようになりました。LLMの支援により、新しい言語の習得や開発スピードが大幅に向上します。
そのような背景から、人間を介さずにLLMが自律的にソフトウェアを開発できるのではないかという期待もあります。本記事では、LLMを活用したソフトウェアの自動生成について調査した内容と、実際にAIエージェント・アプリケーションを動作させた結果をもとに、その可能性と課題について議論します。
ここでのAIエージェントとは、人間から目的を与えられると、行動と自身の行動結果に対する観察により、自律的に目的を達成しようとするシステムを指します。ソフトウェア開発におけるAIエージェントは、コードやドキュメントを検索し、コードを書いて実行するといった行動を取ります。そして、検索されたコードの一部やコードの実行結果をもとに、次の行動を決定していきます。すなわち、LLMを活用してこのようなソフトウェア開発タスクを自律的に実行するソフトウェアがAIエージェント・アプリケーションということになります。
SWE Benchの結果からみえる現状のLLMの課題
まず、LLMのコーディング能力を定量的に議論するために、コード生成の分野で用いられるベンチマークについて説明します。有名なベンチマークとして、Human Eval[1]とMBPP[2]が知られています。どちらもPython言語を対象に、与えられたユニットテストに通るコードを生成するタスクが課せられます。
例えば、以下のような問題とテストが与えられます。
from typing import List
def intersperse(numbers: List[int], delimeter: int) -> List[int]:
””” Insert a number ′delimeter′ between every two consecutive elements of input list ′numbers′
>>> intersperse([], 4)
[]
>>> intersperse([1, 2, 3], 4)
[1, 4, 2, 4, 3]
”””
(HumanEvalより引用)
この問題では、与えられた整数リストnumbersの連続する各要素の間に、特定の整数delimeterを挿入するスクリプトを求められています。
def check(candidate):
assert candidate([], 7) == []
assert candidate([5, 6, 3, 2], 8) == [5, 8, 6, 8, 3, 8, 2]
assert candidate([2, 2, 2], 2) == [2, 2, 2, 2, 2]
(HumanEvalより引用)
実際に筆者の手元の環境でGPT-4に答えてもらうと、上記のテストをパスするコードを書いてくれました。なお、コード生成時にテストコードはLLMには提供しません。
これらのベンチマークにおいて、GPT-4を用いた上で方法を工夫することによって、正答率がHuman Evalでは96.3%、MBPPでは91.8%が出ることが報告されています[3]。
機械学習の分野においてこれだけ高い精度を達成できてしまうと、新たに開発された手法やLLMが、既存手法や既存モデルよりも本当に優れているのか、これらのベンチマークでは比較ができなくなります。そのような背景もあり、SWE-Bench[4]という新たなベンチマークが登場しました。
このベンチマークは、Pythonの有名な12個のオープンソースソフトウェアのIssuesとPull requestをもとにしており、人間の開発者が実際に解決したコーディングの課題から構成されます。そのため、LLMの性能をより現実的な文脈で評価することができます。
このベンチマークでは、パッチファイルを出力することが求められ、パッチファイルを適用したコードが既に用意されたテストに通るか否かによって正解率を評価します。
例として、PythonライブラリのScikit-learn[5]の以下のIssueがテストデータに含まれます。
https://github.com/scikit-learn/scikit-learn/issues/12831
これは機械学習モデルのふるまいに関するIssueで、正解となるパッチファイルは以下のようになります。
diff --git a/sklearn/ensemble/forest.py b/sklearn/ensemble/forest.py
--- a/sklearn/ensemble/forest.py
+++ b/sklearn/ensemble/forest.py
@@ -547,7 +547,10
@@ def predict(self, X):
else:
n_samples = proba[0].shape[0]
- predictions = np.zeros((n_samples, self.n_outputs_))
+ # all dtypes should be the same, so just take the first
+ class_type = self.classes_[0].dtype
+ predictions = np.empty((n_samples, self.n_outputs_),
+ dtype=class_type)
for k in range(self.n_outputs_):
predictions[:, k] = self.classes_[k].take(np.argmax(proba[k],
(SWE-Benchより引用)
このようなSWE-Benchの問題に対して、既存のLLMはせいぜい4.80%程度の正解率しか達成できません。正解できる問題は、ほんの数行の変更で済むような単純なものに限られています。
ではなぜMBPPやHuman Evalではかなり高い精度が出ているのに、SWE-Benchではこれだけ精度が低くなってしまうのでしょうか?
それは、SWE Benchの対象とする課題が、他のコードとの関係性を見ながら、適切なファイルの適切な行に適切なコードを書かなければならないという、他のベンチマークにはない特性があるからです。
例えば先ほどのScikit-learnのIssueの場合、Issueの内容をもとにリポジトリのすべてのファイルの中からensemble/forest.pyファイルがIssueに関連することを理解し、その中のpredictメソッドを見つけ、その中に適切なコードを書いていく必要があります。
Issueの内容によってはコードの様々な個所に影響を及ぼす可能性もあるため、それらすべての箇所に変更を加えなければならないこともあります。後方互換性を維持するために、難しい課題では何十ものファイルを変更しなければならないこともあります。これは実際のソフトウェア開発が直面する難しさとも言えるでしょう。
このようなデータセットを解くために、ベンチマークでの解法ではRetrieval Augmented Generation (RAG)という技術を用いています。RAGは、関連する情報を外部ソースから取得し、それをLLMへの入力に組み込むことで、LLMの生成性能を向上させる手法です。
SWE-Benchのベンチマーク解法では、Issueをクエリとして、プロジェクト内のソースコードを検索し、クエリに最も関連するコードの一部を取得します。そしてその情報をLLMへの入力に加えることで、よりコンテキストを考慮したコードを生成できるようにしています。RAGについては以下の技術記事で解説していますので、興味がある方はぜひご参照ください[6]。
また、RAGではしばしば検索ミスが発生することがあります。検索されたコードが誤っていることによる正答率の低下を区別するために、真の解法で変更が加えられた箇所のソースコードをプロンプトに加えた方法(論文中ではOracle retrievalと呼ばれている)も試しています。そのような工夫にもかかわらず、LLMとしてClaude 2を利用し、4.80%しか精度が出ないのです[4]。
一方で、このベンチマークが解けるということは、ソフトウェアの任意の状態と関連タスクから開発を進められるということであり、この技術の応用可能性はかなり広いと言えるでしょう。
DevinとOpen Devin
2024年3月12日、世界初の完全自律型AIソフトウェア・エンジニアと銘打たれたDevinが発表されました[7]。Devinは、SWE-Benchにおいて13.86%の正答率を達成したと報告されています。Devinの実装は公開されていないので詳細は分かりませんが、テクニカルレポート[8]によると、複数ステップの試行錯誤によって精度が上がったとのことです。デモ動画からも分かるように、DevinはCLIによるコマンドの実行ができ、ターミナルの出力を受け取ることができるので、テストの実行結果をフィードバックとして受け取ってコードの修正をすることができます。このような試行錯誤は人間のソフトウェア開発でも同じことが言えます。
Devinを参考にしたオープンソースプロジェクトとしてOpen Devin[9]が登場しました。Open Devinは、Devinの開発元とは別チームによって開発されたOSSで、公開から半月で1万スターを超えるなど、注目を集めています。
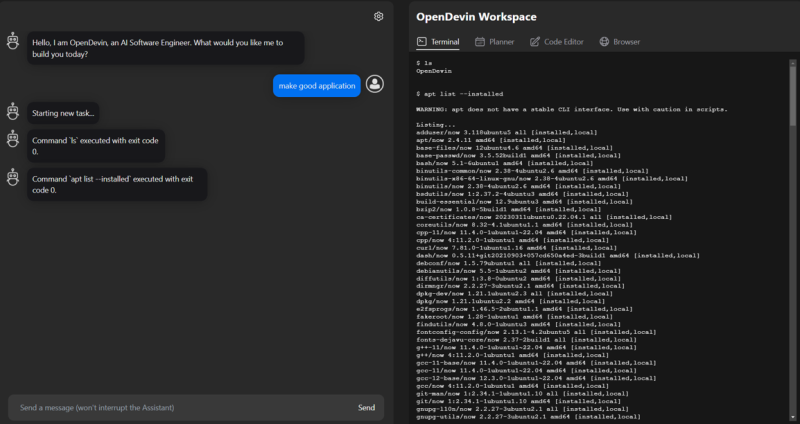
Open Devinでは、バックエンドにDockerを用いたサンドボックス環境を構築し、その中でコマンドラインによる操作やブラウザ検索、コードの解析や改善を行うことができます。これにより、安全かつ効率的にLLMを活用したソフトウェア開発が可能になります。
Open DevinはWebアプリとしても洗練されており、TerminalやCode Editor、Browsingの情報を一つのアプリの画面の中で確認できます。
例えば、Webアプリから実行してほしいタスクの内容や、Unixコマンドを送信して、AIエージェントと協働しながら問題を解決していくこともできます。開発者とLLMとのインタラクションを円滑にし、開発プロセスをシームレスに進められる点が特長と言えるでしょう。
ただし、Open Devinはコードを解析・生成する部分のアルゴリズムやその他の機能はまだまだ改善の余地があり、2024年3月時点の実装ではSWE-Benchは全く解けないでしょう。
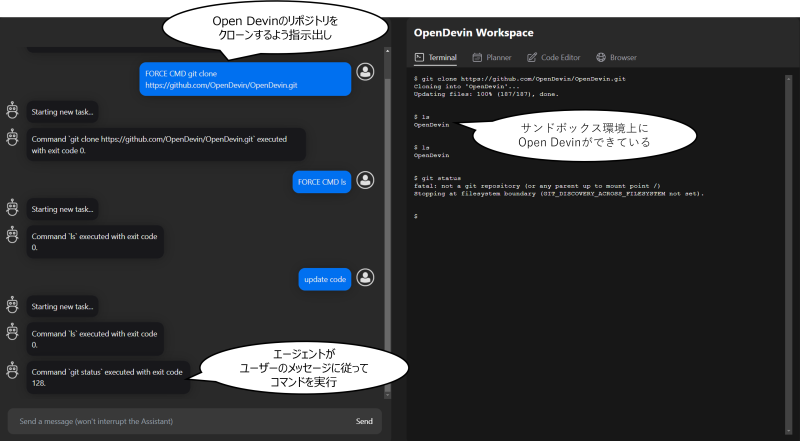
DevinやOpen Devinの登場によって、LLMを用いた自動ソフトウェア開発の可能性が大きく広がったことは間違いありません。例えば、DevinやOpen Devinでは自分自身のソースコードをクローンして改良を加える、すなわち「自分で自分を作る」ことすらできます。
自動ソフトウェア開発の今後
LLMを活用した自動ソフトウェア開発はまだまだ黎明期で、今後の発展の余地は大きいと言えます。DevinやOpen Devinなどの登場により、LLMを用いた自動ソフトウェア開発の可能性が示されましたが、その性能は限定的です。
ソフトウェア開発の対象領域は非常に広範囲に及びます。プログラミング言語の多様性、バックエンドやフロントエンドの処理、UI設計、インフラストラクチャ、非機能要件への対応など、様々な領域が絡み合っています。AIエージェントが完全に自律的なものになるためには、これらすべての領域をカバーできる必要があります。
一方で、LLMの性能は着実に向上しており、分野に対する関心も高く、LLMを活用した様々な関連手法が提案されています。実際にこの記事の執筆期間中にも、Devinと同程度のベンチマークスコアを達する手法が登場しており、これらの実装は公開されています[10][11]。
AIエージェントは、徐々にではありますが確実に、ソフトウェア開発の現場に浸透していくでしょう。それは、開発者の負担を大幅に軽減し、開発のスピードと質を飛躍的に向上させる可能性を秘めています。
参考
| [1] | Chen, Mark, et al. "Evaluating large language models trained on code." arXiv preprint arXiv:2107.03374 (2021). |
| [2] | Austin, Jacob, et al. "Program synthesis with large language models." arXiv preprint arXiv:2108.07732 (2021). |
| [3] | Huang, Dong, et al. "AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation." arXiv preprint arXiv:2312.13010 (2023). |
| [4] | Jimenez, Carlos E., et al. "Swe-bench: Can language models resolve real-world github issues?." arXiv preprint arXiv:2310.06770 (2023). |
| [5] | “Scikit-Learn” https://github.com/scikit-learn/scikit-learn (アクセス日:2024/4/3) |
| [6] | “RAGを利用して国会会議録に基づいて質問に回答するLLMを作る方法” https://developer.mamezou-tech.com/ml/llm/llm-part1/ (アクセス日:2024/4/3) |
| [7] | “Introducing Devin, the first AI software engineer” https://www.cognition-labs.com/introducing-devin (アクセス日:2024/4/3) |
| [8] | SWE-bench technical report” https://www.cognition-labs.com/post/swe-bench-technical-report (アクセス日:2024/4/3) |
| [9] | https://github.com/OpenDevin/OpenDevin (アクセス日:2024/4/3) |
| [10] | John Yang., et al. “SWE-agent: Agent Computer Interfaces Enable Software Engineering Language Models” (2024), https://swe-agent.com/ (アクセス日:2024/4/3) |
| [11] | Zhang, Yuntong, et al. "AutoCodeRover: Autonomous Program Improvement." arXiv preprint arXiv:2404.05427 (2024) |