
第11回:少量データ学習
AI技術チームによる技術発信
AI技術チームの林(リン)です。
現在の社会において、様々な予期せぬ課題に対し迅速に対応できるように、新たな事象の影響下で素早くAIに学習させるニーズが高まっています。例えば、新型コロナウィルスのような、社会に甚大な影響を与えるウィルスが突然現れ、コロナの影響下における社会のデータが不足している状況でもできるだけAIに正しく予測を行わせたい場合があります。また、データ量が膨大になるとデータのラベリング作業や、教師データの整備によるAI開発のコストを、なるべく抑えたいというニーズもあります。少量データ学習 (few-shot learning) はこのような場面に対応できると期待されています。
そこで、今回は少量の教師データでも対応するように提案された少量データ学習の仕組みを紹介します。
少量データ学習の目標
一般的に、機械学習の予測精度は教師データの量と質の影響を受けます。量とはデータの数のことであり、質とはデータの種類ごとの個数の割合や、データのバリエーションなど(例えば自動車の画像データの場合、多数の色や向きの画像が含まれている場合はバリエーションが多いと言えます)を指します。データの数やバリエーションが足りていない場合や、不均衡データなどの課題に対し、データに回転や拡大・縮小などの加工を施すデータ拡張などの手法により学習データの量とバリエーションを増やす工夫が必要です。
しかし、データ拡張により学習データの量とバリエーションを増やしても、予測精度を上げることには限界があります。例えば、ある画像認識の機械学習モデルを学習する際に、教師データとして「猫」と「犬」といった二つの種類のみを使用していた場合を考えてみましょう。仮に、このモデルに「鳥」を予測させようとした場合、教師データには「鳥」というラベルがないため識別できません。無論、教師データに「鳥」の画像を追加しモデルを再学習しなおせば問題は解決できそうですが、もし「鳥」の画像がたった数枚しかないデータセットで予測精度をできるだけ上げたい場合は、どのような工夫をすれば良いでしょうか。
一度機械学習の範囲から離れ、この問題に対して人間がどう対応するのかを考えてみましょう。仮に今までに「猫」と「犬」しか見たことない人に、たった一枚の「鳥」の写真を見せた場合、この人はすぐに鳥の姿を認識することができるでしょう。人は画像を見ながら、猫や犬は足が4本なのに対して、鳥は足らしきものを2本持つという特徴や、鳥が猫と犬が持っていない部位 (翼) を持つといった動物の種類ごとの特徴を認識することができます。人間のこのような優れた認識能力に少しでも近づき、認識対象のデータが少数しかない場合でもできるだけ高い精度で識別しようとすることが少量データ学習の目的です。
少量データ学習の精度は、予測したいラベルの数とラベルごとのとるデータ数に強く影響を受けます。各ラベルにおいてデータがただ1個の場合は、「ワンショット」と呼ばれています。もっと極端な場合が、ゼロショット(予測したい対象のデータを新たに学習することなく行う予測)です。
少量データ学習の手法
少量データ学習の手法は数多く提案されています。先ほどの例のように、識別したいデータ以外のデータ (先ほどの例では犬、猫) を用いて一度モデルを学習し、識別したいデータ (先ほどの例では鳥) でモデルを微調整するという二段階の学習手法はファインチューニングと呼ばれ広く利用されており、他の手法と比較しても遜色はないパフォーマンスが報告されています[1]。
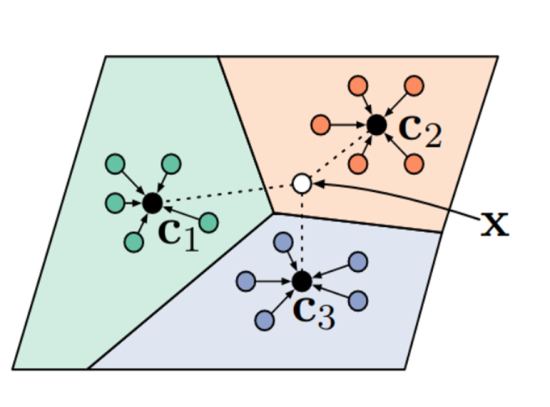
ファインチューニングの他にも、メタ学習と呼ばれるアプローチがあります。これは少量データ学習に適した形に「モデルの学習の仕方を学習する」というものです。ここでは、提案されているメタ学習手法の1つであるプロトタイプネットワークを紹介します[2]。深層学習による画像認識では一般に、モデルにより特徴抽出を行い、特徴量空間における位置関係でラベルを予測します。図(1)は特徴量空間におけるデータの例で、丸はそれぞれ画像データに対応し、その抽出された特徴によりこの空間上での位置が決まっています。この例では識別すべきラベルは3つあり、それぞれの色がラベルに対応しています。プロトタイプネットワークでは、教師データ (色付きの丸) の平均から特徴量空間上の代表点をクラスごとに設定し (C1, C2, C3)、代表点からの距離で推論対象のデータがどのラベルになるかを予測します。最も近い代表点のラベルが予測結果となり、他の代表点から遠いほど、予測結果が正しい確率が高いとみなします。プロトタイプネットワークでは、事前学習により、少量データ学習の予測結果がはっきり出るように、つまり対象データが正しいラベルの代表点に近くなり、他の代表点から遠くなるように特徴量の抽出方法を学習させます。このことにより、未知のデータに対して少量データ学習を行う際にも予測対象のデータが各ラベルの代表点の中でも正解ラベルの代表点に近くなりやすいことが期待されます。
近年、基盤モデルと呼ばれる、大量のデータで事前学習されており多数のタスクに利用可能なモデルが注目されています。代表的な例には自然言語分野で活躍しているBERTや ChatGPT でも使われているGPTモデルがあります。これらのモデルを利用すると少量データでも予測を行うことができ、さらには予測させたい対象についての学習データなしでもゼロショットで予測を行うことができると報告されています。例えば、BERTモデルに対してクラス分類器を追加することで、新たな学習データを加えなくても新しいタスクを解くことができます。他にも、学習データと自然言語データの対応関係を学習させた基盤モデル「CLIP」は、ゼロショットの画像認識を実現できたという点で話題になっています。論文内では様々な画像認識データセットに対する評価が行われましたが、高精度を実現可能で広く活用されているImageNetで学習済みのモデルと遜色ない、もしくはさら優れた性能をゼロショットで達成することが可能であると報告されました[3]。
図(1)プロトタイプネットワークにおける特徴量空間にデータをマッピングした例。色は教師データが属しているラベルを表しています。Xは予測しようとしているデータで、白い円の位置は特徴量空間にマッピングした位置を表しています。(画像出典:https://arxiv.org/abs/1703.05175)
現状と今後への期待
機械学習の活用場面では、教師データの量と質の確保は課題となることが多く、少量データ学習により機械学習モデル作成において教師データを準備するコストの低減が実現できれば非常に有益だと考えられます。また、商業的な利用に限らず、大量な教師データの取得が困難な場面でも応用できると期待できます。例えば、災害の被害地域等、人が立ち入ることが困難な場所から大量なデータを入手することはできないため、AIの利活用は一般には難しいと考えられます。少量データ学習の活用により、こういった場面のAI開発を促進できるとすれば、それは素晴らしいことです。
現在、少量のデータによる予測を行なっている代表的な例には顔認識が挙げられます。1枚の顔写真を事前に用意しておくだけで人物認識ができるようなサービスもあります。画像以外でも、音声認識や文書作成など、様々な領域で展開されており、今後もニーズは高まると予想されます。現在よく利用される画像認識のタスクは「分類」、「物体検知」、「セグメンテーション」が挙げられますが、「分類」以外のタスクへの適用に対してはより未成熟な状態です。物体検知やセグメンテーションの領域ではまだ研究も十分発展しておらず、汎用的な成果を達成することが難しいのが現状です。すなわち、少量データから最大限度な情報を絞り出す手法は、まだまだ発展する余地があります。少量データ学習の活用が広がると、社会におけるAIの利用が活発になると考えられるため、これからも少量データ学習の発展を期待しています。
参考
| [1] | Dhillon, G. S., Chaudhari, P., Ravichandran, A., & Soatto, S. (2019). A baseline for few-shot image classification. arXiv preprint arXiv:1909.02729. |
| [2] | Snell, J., Swersky, K., & Zemel, R. S., Prototypical Networks for Few-shot Learning. arXiv preprint arXiv:1703.05175. |
| [3] | Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR. |