第10回:テキストから画像生成を行うAIモデルの紹介
AI技術チームによる技術発信
こんにちは、AI技術チームの松永です。
最近AI業界で大きな話題になっている、テキストから画像生成を行うAIモデルについて、今回はご紹介していきたいと思います。色々な企業から提供されている画像自動生成サービス、ビジネス利用の可能性、問題や課題になりそうなこと、使用例について、本記事で紹介していきます。
テキストから画像生成を行うAIモデル
画像の生成モデルの代表手法には、以前よりGAN(Generative Adversarial Network, 敵対的生成ネットワーク)、 VAE(Variational Autoencoder, 変分自己符号化器)などがありましたが、2022年に入り、相次いでテキストから画像生成を行うAIモデルが発表されました。
以下に、その代表的な例を紹介します。
【DALL-E2 拡散モデルによる高精度な画像生成 】
OpenAIは、CLIP(Contrastive Language-Image Pre-training)を組み合わせた「DALL-E 2」を発表しました(ご参照)。CLIP は基盤モデルと呼ばれるモデルの1つで、テキストと画像の関係を大量に事前学習しておくことで様々なタスクに活用可能です。この拡散モデルとは、ノイズ画像を用意し、徐々にノイズを取り除いていく操作を行うことで画像を生成するモデルです。ノイズを除去していくプロセスをモデル化するために、まずはその逆であるノイズを徐々に付与していくプロセスをモデル化することが、拡散モデルのポイントです(拡散モデルの詳細については、こちらの論文をご参照ください)。拡散モデルは、GANやVAEよりも高精度の画像を生成することに成功しており、様々な分野への応用が期待されています。
【Stable Diffusion 計算コストを低減させる潜在拡散モデルを利用】
拡散モデルは当初計算量を必要としましたが、Stability AI が開発した「Stable Diffusion」では、計算コストの低いより低次元の潜在空間上で学習・推論する潜在拡散モデル(Latent Diffusion Model)が使われています。
【Novel AI 高精度のアニメキャラクター・二次元イラストの生成】
「Stable Diffusion」と同じ潜在拡散モデルをベースにしたといわれている「Novel AI」は、Anlatan社によって運営されており、高精度のアニメキャラクター・二次元イラストを生成できることで話題になりました。「Novel AI」は、充実したタグ情報を付与された画像を学習に利用することで精度を向上させたようですが、画像の無断転載がされている二次元画像サイトからデータセットを作成したことが、問題視されています。
【Imagen 低解像度の画像から徐々に解像度が高い画像を生成するカスケード拡散モデル】
Googleは、カスケード拡散モデル(CDM:Cascaded Diffusion Models)を用いて、「Imagen」を発表しました。カスケード拡散モデルでは、複数の拡散モデルを連鎖的(カスケード)に構築します。低解像度の画像を最初のモデルとして生成し、徐々に解像度が高い画像を生成していきます。最終的に高解像度の画像の生成が行われます。
【“呪文”によってSNSでの画像の自動生成を普及】
Midjourney研究所が発表した「Midjourney」に使われている技術は非公開ですが、拡散モデルベースの技術が使われている模様です。2022年6月に「Midjourney」が、8月に「Stable Diffusion」が発表されてから、お手軽にすごい絵が作れるということで、瞬く間にテキストから画像生成を行うことが話題になりました。様々な品詞を組み合わせた複雑なパターンのテキストを入力するとより良い画像ができることから、入力テキストが「呪文」と呼ばれることがあります。呪文というワードの面白さや、テキストを入力するだけで簡単に絵を表示できることから、SNS上で自動生成した画像を紹介することが流行しており、それまでAIとは縁のなかった人々も(知らないうちに)AIを楽しんでいるという現象が起きています。
使い方
「DALL-E 2」は、アカウントを作成すると、無料で使用することができます。より多くの画像を生成したい場合は、115クレジット(約460画像相当)で$15を支払う必要があります。
「Stable Diffusion」は、オープンソースとなっており、人工知能のコミュニティであるHuggingFaceやGithubでコードやドキュメントが公開されています。Google Colaboratoryやローカル環境で環境を構築することもできますし、HuggingFaceのWebサイトに用意されている動作デモのページで画像生成を行うこともできます。
「Novel AI」は、有料サブスクリプションサービスとなっており、Webページからアカウント登録をしたあとに使用することができます。
「Midjourney」は、Discordというフリーチャットツールのアカウントを取得したあとにWebページから使用することができます。
ビジネス利用の可能性
では、テキストから画像生成を行うAIモデルは、どのようなビジネス利用が考えられるでしょうか?
画像生成をユーザー自身ができることから、発注コストなしで(計算機コストはかかりますが)自由なイラストを作成し、それをビジネス利用することが考えられます。自社商品のパッケージデザイン、ロゴ、プレゼンテーション資料用の画像など、色々な場面で使用することができると思います。
他には、数字の大小や方程式といった文字で表示することが一般的なものに対してイメージを作成することも、アイデアの一つとして挙げられます。専門家にしか理解が難しいことを、わかりやすいイメージにし、多くの人に対する説明に使うことができるかもしれません。
また、AI開発において重要で、かつ時間・コストがかかる学習データ作成に対して、画像自動生成モデルを使うことによって容易に大量のデータを準備することもできます。作り方の工夫は必要ですが、コストを削減しつつ、AI開発ができる可能性があります。
問題・課題
画像生成を行うAIモデルは、学習のための入力・出力として画像を扱うことで、著作権が問題になってきます。豆蔵は法律の専門家ではないので、ここでは詳細な解説は控えさせていただきますが、AIによる画像生成の著作権について説明しているブログを紹介いたしますので、ご参考ください。STORIA法律事務所ブログ。
また、実際に使用する際の問題としては、以下のことが挙げられます。
- 不適切な画像の生成
テキストを工夫してきれいな成功画像ができる過程において、気持ち悪い画像や社会的に不適切な画像が出てくる可能性もあります。ユーザーとして使用する際には気をつけないといけません。
- 過大なクラウド利用料の発生
「Stable Diffusion」はオープンソースなので、自分で用意したクラウド環境で使用することができます。このような場合、知らず知らずのうちに、計算コストが膨大になってしまい、支払いが難しくなることがあります。計画的に、無理のない範囲での利用に留めておきましょう。
- 入力テキストの呪文化(複雑化)
綺麗な画像を生成するため、入力テキストが呪文化してしまうことがあります。画像を作るうえでは楽しい要素の一つになりますが、画像生成処理が異なるサービス間でのテキストの転用がしづらいことや、複雑なテキストが必要とされます。これらは、ビジネスで利用する際の課題になるかもしれません。関連して、呪文化したテキストでは、細かい修正(顔のサイズを小さくする、人の位置を変えるなど)ができないことがあります。自動生成を行っても、手動で微修正を行う必要があるということです。
- フェイク画像の生成
災害の画像を自動生成し、それをSNSに投稿するといった、悪意を持った偽の画像の拡散といった新しい問題も発生してきました。落ち着いて情報ソースを確認し、デマや誤った画像ではないかを確認することが必要です。
使ってみた!
実際に、どういった画像が作られるのか筆者もサービスを使ってみました。
今回は無料で利用できる「Stable Diffusion」をHuggingFaceのページから使用しました。
- 入力テキスト「IT technology team is working in the office」
- 入力テキスト「IT technology team」

男性社員、PC、眼鏡、シャツ、大きな窓があるオフィスといったようにIT系の会社によくある画像が生成されました。PCや机は実際に存在している感じのものになっていますが、人間の顔が変な人も描かれています。理由は不明ですが、「IT technology team」のみですと、女性社員も含まれるようになりました。こういったAIによるジェンダーバイアスは、知らない間にユーザーに対して不公平な表現を生み出す危険性がありますので注意が必要です。
- 入力テキスト「sin(theta)*sin(theta)+ cos(theta)*cos(theta)=1」

円の方程式をテキストにして入力したところ、円っぽい画像を生成することができました。演算子をテキストで表現することは難しいですが、今回は方程式が表す内容に近いイメージの画像になりました。
- 入力テキスト「beautiful autumn leaves in the mountains」
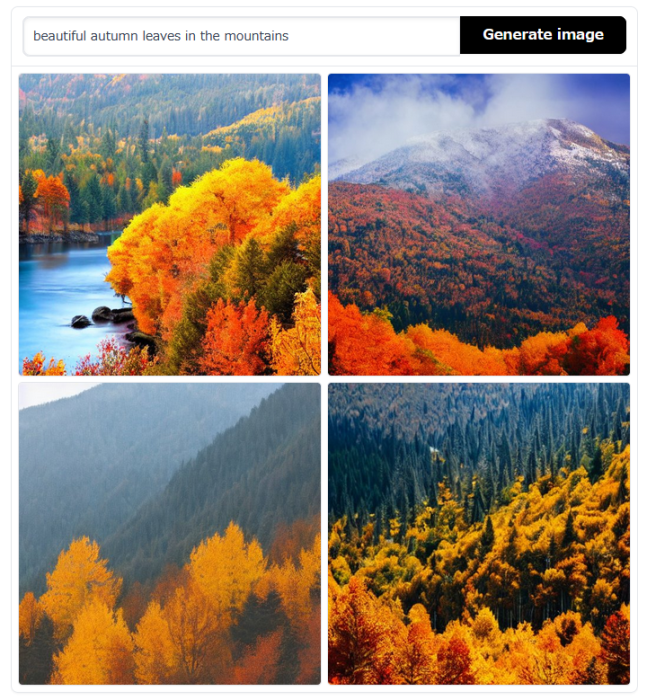
(記事執筆時は秋だったので)紅葉のテキストを入力したところ、美しい紅葉の画像を生成することができました。こういった風景の画像は、世の中にたくさん存在しているので、文字通りの画像が生成されやすいのかもしれません。紅葉した木と針葉樹が含まれる画像が作られやすいことも現実に即しているので興味深い結果です。
入力テキストの指定が英語のサービスが多いですが、面白い画像を作成することが簡単にできます。皆さんもぜひ画像自動生成サービスを使っていただき、身近なAIモデルを感じてみてください。
それでは、皆さん、良いお年をお迎えください!
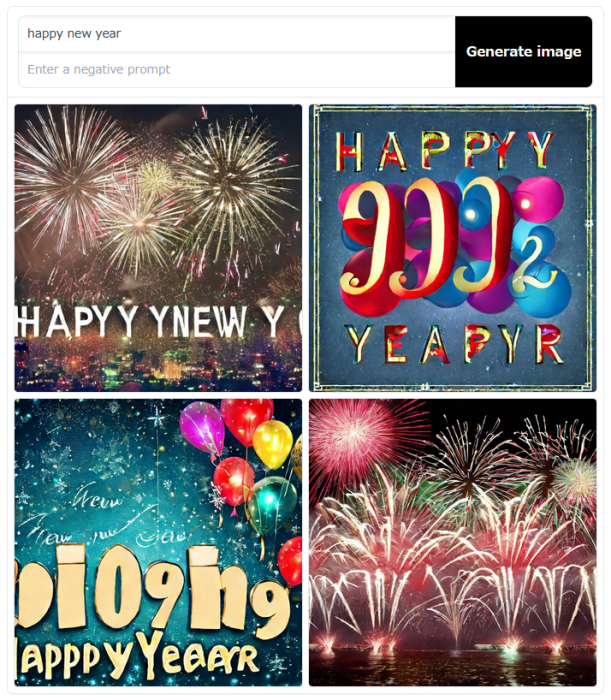
入力テキスト「happy new year」