
第5回:アノテーションコストを低減する手法について
AI技術チームによる技術発信
AI技術チームの米丸です。今回は機械学習において欠かせないアノテーション(教師データ作成)のコストを低減する方法であるアクティブラーニング(注1)についてご紹介します。
アクティブラーニングとは
機械学習は教師あり学習と教師なし学習に区別され、世の中でAIと謳われるシステムの大部分は教師あり学習を利用しています。
教師あり学習は、課題によっては人手でラベル付けされた教師データを用意する必要があります。しかし、予測精度を高めるためには大量、かつ正確な教師データが必要となるので、ラベルを付ける作業(Annotation; アノテーション)のコストは非常に高くなってしまいます。アクティブラーニングとは、予測精度を向上させるのに有用なデータを少量サンプリングすることでこのアノテーションコストを低減する手法で、大きく以下の3つに分類されます[1]。
- Membership Query Synthesis
実際のデータ分布をもとにラベルを付けるべきデータを疑似的に生成する手法 - Stream-Based Selective Sampling
各データに対してラベルを付けるかどうかを判断する手法(各データを次々と流して判断することからStream-basedという名称となった) - Pool-Based Sampling
ラベルの付いてないデータの集合(プール)からモデルを学習させる上で最も効果が高いと考えられるデータをサンプリングする手法
これらの中ではPool-Based Samplingが一般的であり、今回はPool-Based Samplingの2つの代表的な手法を説明します[2]。
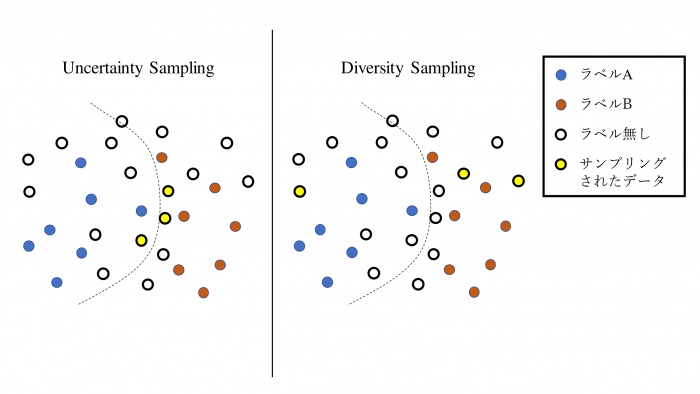
Uncertainty Sampling
機械学習モデルの決定境界に近く、分類が難しいデータをサンプリングする方法。以下のような手順でアノテーションを行います。
- 一部のデータにラベルを付ける
- モデルを学習させる
- 学習したモデルをラベルの付いてないデータに適用して、各データの不確実度スコア(uncertainty score)を求める
- 各データを不確実度スコアの昇順に並べ、上位N個のデータにラベルを付ける
- 4でラベルを付けたデータを教師データとして2に戻る
3の不確実度スコアを求める方法はいくつかありますが、説明が長くなるので今回は割愛したいと思います。また、「N」やループの回数は、求められる精度とアノテーションや学習のコストから総合的に決める必要があります。
Diversity Sampling
実際のデータ分布を代表するようなデータをサンプリングする手法。具体的には主に以下の3つの手法に大別されます。
- Model-based Outlier Sampling:外れ値検知により機械学習モデルにとって未知のデータをサンプリングする方法
- Cluster-based Sampling:クラスタリングなど統計的な手法を用いて意味のある希少なデータをサンプリングする手法
- Representative Sampling:ターゲットドメイン(機械学習が適用されるデータ領域、第3回:ドメインシフトと機械学習の性能低下を参照)の分布を代表するようなデータをサンプリングする手法
Uncertainty Samplingには、決定境界付近のデータしかサンプリングされず実際のデータ分布を反映できないという欠点があります。一方で、Diversity Samplingでサンプリングされるような決定境界から遠く各ラベルの分布を反映するデータは数が多いためアノテーションコストが比較的高くなるという欠点があります。そのため、これらの2つの手法は互いの欠点を補うため組み合わせて利用されることが多いです。
活用例
アクティブラーニングが活用される分野として自然言語処理が挙げられます。自然言語処理とは、コンピュータに言葉を理解・処理させる技術のことで、この分野においてもアノテーションコストは大きな課題となっています。自然言語処理は機械翻訳、テキスト分類、意味解析、情報抽出などのタスクに分けられますが、その各タスクにアクティブラーニングの適用例があります。例えば、[3]では畳み込みニューラルネットワークを利用したテキスト分類にアクティブラーニングを利用しており、埋め込み空間(注2)で最も影響が大きなデータを抽出する手法を提唱しています。
アクティブラーニングの今後について
AIの爆発的に普及に伴いアノテーションコストを低減することはビジネスにおいても重要な課題となり、近年数多くのアクティブラーニングに関する研究が進められています[4]。今回の記事ではアクティブラーニングの概要と活用例を説明した程度ですが、機会があればより具体的な最新の手法について説明したいと思います。また、画像処理や自然言語処理においてアクティブラーニングは実用化されつつありますが、その実用性検証はまだ十分になされていないので、今後実社会のデータに対するアクティブラーニングの実用性も検証して記事で紹介できればと思います。
参考文献
| [1] | Burr Settles. 2009. Active learning literature survey. Technical Report. University of Wisconsin-Madison Department of Computer Sciences. |
| [2] | Robert Munro. 2021. Human-in-the-Loop Machine Learning Active learning and annotation for human-centered AI. Manning Publications Co. |
| [3] | Ye Zhang, Matthew Lease, and Byron C. Wallace. 2017. Active Discriminative Text Representation Learning. Proceedings of the AAAI Conference on Artificial Intelligence 3386ー3392 |
| [4] | P. Ren, Y. Xiao, X. Chang, P.-Y. Huang, Z. Li, X. Chen, and X. Wang. 2020. A survey of deep active learning. arXiv:2009.00236 |
| 注1) | 教育の分野ではアクティブラーニングは「生徒や学習者が自ら能動的に学びを進められるようなグループワークやディスカッションといった学びの場の中での学習」を意味します。ここでは、あくまでAI分野におけるアクティブラーニングの解説なのでご注意ください。 |
| 注2) | 言葉(文字列)はそのままの形では機械学習で処理できないので、計算可能なベクトルに変換する必要があります。その変換操作を埋め込み(embedding)と呼び、埋め込み空間とは変換後のベクトル空間を指します。 |