
豆寄席第25回『自治体の住民と法人をモデリングしよう』参加レポート
本稿は、豆寄席第25回の開催報告です。
開催概要
| タイトル | 自治体の住民と法人をモデリングしよう |
| 講演者 | DBC代表 渡辺 幸三氏 |
| 開催日時 | 2022年12月21日(月)18時00分~19時30分 |
| 講演概要 | 世帯や戸籍を含む住民情報、多種多様な業種別の管理項目を含む法人情報。自治体DXのために、それらをどのようにモデリングすべきなのでしょう。そのひとつのアイデアを説明します。 |
講演の流れ
以下のような流れでDXのために必要となる根本的な考え方を解説後、自治体システムのDXに向けて新たなデータモデルを使ったアイデアをお話しいただきました。
- 一般的なシステム設計手順について
- DXのためのシステム設計手順について
- 「X-TEA Modeler」で作成したデータモデルの説明
- データモデルを元に作成した自治体システムのプロトタイプの実演
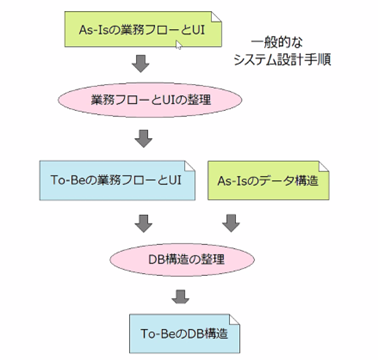
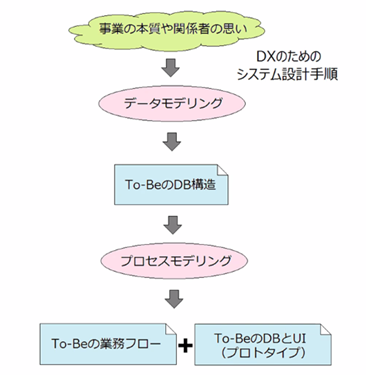
一般的なシステム設計手順とDXのためのシステム設計手順の違い
最初にDXが失敗する理由として一般的なシステム設計手順の例をあげ、この場合だと現行の業務フローとUIを前提とした進め方のため、どんなに整理したとしてもシステムの『抜本的な』変更は絶対にうまくいかないということを説明されました。これはそもそも変更に必要なインプットが無いためですが、DXの現場ではたびたび起こってしまうことだそうです。
実際の例として、デジタル庁が公開している住民基本台帳のER図を紹介され、以下のような問題点を挙げられています。
- PKとFKが載っているだけで他の属性が全く載っていないため、テーブルの意味が分からない。
- 物事が分かっている人だけにしか分からない。図面は分からない人でも分かるようにすべき。
- 図の矢印なども一目でその意味が分からない。
現行システムを分析し、整理してもこのような難解な図しか生まれない状況から、自治体システムのDXを実施するのは困難であることを改めて説明されました。
では、DXをちゃんと進めるためにはどうすればよいのか?重要なのは、データモデルに基づいてプロセスモデリングを行うことだそうです。多くの技術者はUIを見ることでデータモデリングができると勘違いしがちですが、これは最終的に古いシステムと似たようなものが出来上がってしまう原因であると説明されていました。そのため、DXのように抜本的な変更を行うためには、データモデリングの後に業務フローやUIなどを考え直していくといったクリエイティブな考え方が大切だと教えていただきました。特に、自治体システムのようなデータ管理システムの核となるのは管理したいデータの構造そのものとなるため、まずはその構造から考えていく必要があるそうです。
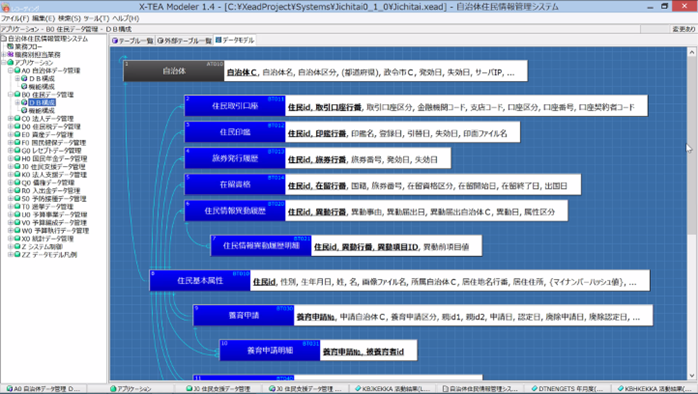
「X-TEA Modeler」で作成したデータモデルの説明
自治体システムDXを行うためのデータモデルのアイデアとして、渡辺氏は自らが開発した「X-TEA Modeler」という設計ツールによって作成したモデルを紹介されました。(参考:X-TEA Tools and Resources - X-TEA Modeler (coocan.jp))
データモデルの表記法としては以下のようなもので、各テーブルは属性を横一列に並べて表記します。また、データ間の関係は派生関係、親子関係、参照関係で表すことができます。

この表記法をもとに、渡辺氏は作成した自治体システムのデータモデルを説明しながら、主に以下のような特徴をあげられました。
- 住民それぞれを表した「住民基本属性」のテーブルにあるマイナンバーカードの番号はハッシュ値が置かれている(マイナンバー自体はカードにしかなく、逆算は不可能となっていて安全性が高い)。
- 本籍地は本人が自由に決められるものであり、データとして管理する意味があまりないと考えているため、今回のモデルから外している。
- 「福祉格」という福祉行政上の人格を表したテーブルを定義しており、年度別の支援内容を自治体ごとに管理できる。
所感
筆者はまだDXに関する業務の経験はないのですが、今回参加したことで既存のDXの問題点とその解決に向けた考え方について深く学ぶことができました。特に、モデリングから始めていくことの大切さについては豆蔵としても核になっている考え方のひとつであるため、改めて重要なことであると感じました。
また、今回紹介されたデータモデルは全体的に分かりやすい構成で、既存のものよりも合理的になっていると思いました。渡辺氏が開発された「X-TEA Modeler」は無料ツールとなっておりますので、データモデリングの手法の一つとして、ぜひ自分でも活用してみたいと思います。
今後の 豆寄席 へのご参加もお待ちしております!